
Here’s an excerpt from the piece on Tech Crunch that had everyone talking. “Imagine a future where individuals can illustrate their progression of lifelong learning and training and its links to their real-world performance. In this version of the future, the once-ubiquitous résumé has been ousted by the experience graph.” Read The Full Article
Data
The Future of Crypto DApps and the Ethereum Project Community
Possibility to Explore
Crypto ÐApps Go From Fringe to Foundation by 2025
By 2025, the Ethereum network will find mainstream success as ÐApps (decentralized applications) emerge from individuals, businesses, civic institutions and governments eager to develop products and services based on a radical mix of trust, transparency and automation. Within a decade Ethereum – and the idea of cryptographically secured programmatic decentralized applications will likely move from today’s fringe to a foundation of social innovation. Read more
Four Futures of the Own Your Own Data OYOD Movement
 Summary: OYOD or Own Your Own Data is a simple, radical (likely unattainable) idea based on new tools, behaviors and policies that allow people to control their data and grant access to third parties. The early stage reality of an OYOD-ish future will likely be messy and imperfect — but still better than what we see today. Read more
Summary: OYOD or Own Your Own Data is a simple, radical (likely unattainable) idea based on new tools, behaviors and policies that allow people to control their data and grant access to third parties. The early stage reality of an OYOD-ish future will likely be messy and imperfect — but still better than what we see today. Read more
Working with Intelligent Assistants

Soon after 2020, service and knowledge workers might begin to see their own personal Intelligent Assistant as the key to their workplace success.
The age of the Intelligent Assistant is close but will take years and decades to unfold. Rather then envision Hal from 2001:A Space Odesssy or dream of Scarlett Johannsen’s voice “Samantha’ from the movie Her — focus on understanding the implications of systems like IBM Watson or Kensho’s Warren at work.
From Apple’s Knowledge Navigator to Mindmeld: The Evolution of Personal Assistant
Expect Lab‘s Marsal Gavalda walks us through 26 minute video of techno-optimistic geek goodness by looking at present day enthusasiam for personal assistant technologies and some of the historical milestones that brought us here.
Why the enthusiasm in 2014? The Spike Jonze’s movie Her gets credit for popularizing the idea of a likeable and lovable personal assistant but the real source of optimism is just old fashion innovation from our learning curve. Artificial intelligence sub-domains of machine-learning and deep-learning (used for real-time understanding of natural language) are making steady progress. The past few years have given the world very positive advances around knowledge graphs for natural language, sentiment analysis of unstructured data, and anticipation oriented recommendation systems.
The next five years will bring hype and real hope for functional contextual search and conversation-based experiences that make personal assistant beyond 2020 likely and doable. I have waxed poetic about Expected Labs MindmeldAPI and have the same respect for companies like NextIt and Artificial Solutions (Indigo) who are creating the early market demand.
My highlights from his talk: min 2:20 Github workflow and productivity visualization]
https://www.youtube.com/watch?v=fKen7IkdAm0
** **
Marsal mentioned the Apple 1987 video of the Knowledge Navigator
https://www.youtube.com/watch?v=QRH8eimU_20
** **
Garry’s Tags: Personal Assistant;
Cognition-as-a-Service: Rent Learning Machines Inside the Cloud
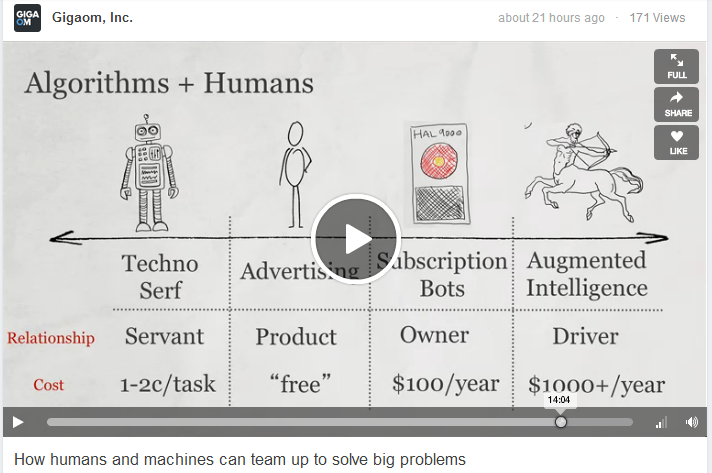 Summary: Siri and IBM Watson for everyone? Organizations might soon be able to rent brain power by the hour from the cloud – creating a new marketplace for contextually-aware and adaptive applications powered by software programs that learn from real-world human user interactions. Our educational and workflow experiences might soon access cogntive computing applications to learn more effectively and make better decisions on complex issues.
Summary: Siri and IBM Watson for everyone? Organizations might soon be able to rent brain power by the hour from the cloud – creating a new marketplace for contextually-aware and adaptive applications powered by software programs that learn from real-world human user interactions. Our educational and workflow experiences might soon access cogntive computing applications to learn more effectively and make better decisions on complex issues.
Companies are starting to experiment with business models to deliver cloud based cognition in the form of ‘contextual and cognitive computing’ via API Engines and stand alone software solutions.
Contextual & Cognitive Computing
Cognition as a Service is just a buzzword today. It is far from defined! The most likely path towards bringing cognition level abilities to organizations will likely pass through stages. The first will be an evolution towards contextual experiences followed by more sophisticated ‘IBM Watson’-like applications.
Contextual web experiences move us from information being delivered by ‘keyword’ connections to a more personalized sense of the right ‘context’ for our lives based on: location, activity, life experiences and preferences, et al. Contextual experiences are more personalized and certainly ‘learn’ from interactions with users – but there is a new paradigm of ‘cognitive’ systems that elevate the experience.
Cognitive Computing is an era where software systems learn on their own and can teach themselves how to improve their performance. IBM Watson is today’s most sophisticated cognitive application. Watson is currently providing decision support for cancer treatments at Sloan Kettering, financial service support for companies such as ANZ and CitiGroup, and working to evolve the retail customer experience for Northface.
Cognition as a Service?
In practical terms this means an organization might be able to buy ‘as a service’ (e.g. not an application they paid to develop or maintain) – natural language processing for human-like Question & Answer interactions.
Companies pushing both of these capabilities are simultaneously trying to improve performance, integration and business model design. Early industry adopters will range from health, finance, energy, education, et al. Industries with connected data and a need for augmenting human knowledge building. Early adopters industries will likely have lots of data and compliance heavy regulatory frameworks.
The cloud-based business models of ‘software-as-service’ and ‘platform/infrastructure-as-service’ are the most likely first path for contextual and cognitive platforms. Startups such as Expected Labs are bringing their API engine MindmeldAPI into the marketplace. IBM Watson is hedging its bets by delivering stand alone solutions and also opening up its API to developers.
Developers are just now getting their hands dirty with advanced contextual computing applications. Truly transformational applications will likely emerge 2015-2025.
Companies to Watch:
AlchemyAPI, Declara, Intelligent Artificats, Grok, Saffron, Stremor PlexiNLP and Vicarious are companies with products designed to build knowledge graphs and natural language interactions that have contextual and cognitive computing style capabilities.
Video to Watch – Range of Business Models?
Sean Gourley – Founder of Quid has been wrapping his head around the future of mankind working ‘with’ machines for several years. I’ve seen Sean’s talk evolve over two years– and it continues to be among the most solid framings of this massive transition towards ‘augmented intelligence.
This is a great talk by Sean Gourley from the March 2014 GigaOm Data Structure Conference.
***
I’ve posted Expected Labs Mindmeld videos here
***
Looking for something more mainstream and business oriented:
Garry’s Diigo Tags on: IBM Watson;
OYOD Own Your Own Data Movement
Summary: What type of data will make people want to protect it? Forget about social web data, personal health and lifelong learning data and analytics offer the most compelling niches to raise public awareness to own and control our personal data. Health data goes beyond clinical electronic health records (EHR) to include lifestyle analytics currently championed by the quantified self movement. Learning data goes far beyond high stakes test scores to include life-enriching experiences captured via the ExperienceAPI (TinCan) standard and controlled by the learner.
>> >>
Connected Data innovations for Health-Wellness & Lifelong Learning shape an experience industry
Where might the Own Your Own Data (OYOD) movement find its momentum?
The vision of an Own Your Own Data (OYOD) future is a world of informed and empowered individuals who can control their own personal data and leverage (via opt-in) it with companies, organizations and governments as they see fit.
Elevating data literacy and social norms on how to control, protect and apply our own personal data will take years to unfold. As of early 2014, the ‘OYOD movement’ is dispersed and off the radar. By the end of the year things could be very different. Projects such as IrisPact (pronounced I RESPECT) and media attention on personal data could shift expectations and set the stage for OYOD policies to be implemented.
Where might OYOD gain momentum? The near term target is tilting the balance of power over our social web data back to the user. Protecting personal data and advocating for ownership within social web environments is a worthy goal but late in the game to try and change the rules. Most existing social data projects are shallow efforts essentially linked to controlling our own precision advertising profiles.
If we are looking for arenas that an Own Your Own Data (OYOD) movement could emerge– healthcare and lifelong learning are two possibilities.
Health
The idea pushed within the healthcare and wellness space is broadly known as Personal Health Records or Electronic Health Records (EHR). These platforms allow individuals to gather, protect, share and synthesize individual and family health data records. It is an important transition but insufficient in understanding health-wellness issues beyond clinical setting. Lifestyle health analytics currently found within platforms and APIs from the quantified self community could compliment EHR records to give a more complete real-world picture.
Imagining a world with ‘ownership’ of personal health data is a complicated futures scenario, but plausible and certainly powerful enough to build popular support for ‘OYOD’ policies.
Health Data Projects to Watch:
BlueButton (US); OpenHealth Data (UK); SMARTPlatforms; Dossia; Patients Know Best; MyPHR; Indivio; Open EPIC; Kaiser Permanente Interchange, Atena CarePass, et al.
Learning
In recent years we built our ‘social graph’ that outlines who we know and how we know people by relationships. In the next decade many of us will build our own ‘learning graph’ of what we know and how we know concepts across a wide range of domains.
Building a data-driven ecosystem for controlling our learning graphs is complicated. It is never wise to try and place bets on data standards – but I am bullish on the long-term impact of two enabling foundations to record and leverage lifelong learning experience data.
The first concept to watch is: ExperienceAPI (or TinCanAPI) the next generation (post SCORM) standard application protocol of ‘activity statements’ (I did this…) that allow us to choose when we capture learning experiences. Learning activity statements can be online or offline – within school, work settings or walking in a park. (e.g. I read x-book. I attended x-workshop. I wrote y-book. I earned a masters degree from x-university. I watched x-TED talk. I visited x-museum exhibit. I took photographs of x-flowers. I read a NYTimes article on x-topic).
These ExperienceAPI statements are stored in a LRS (Learning Records Store) platform that gives individuals control over which “I did this…” life experience statements can be shared with other people, institutions or companies. Access to specific LRS data streams allows organizations to dynamically adjust information and experiences to individuals.
There are significant barriers to imagining an OYOD world of lifelong learning but there are paths forward which I will explore in future blog posts.
Learning Data Project to Watch:
ExperienceAPI (TinCanAPI), WatershedLRS, SaltboxWAX LRS;
Knowledge Graphs; Adaptive Learning Platforms
There are other angles to Lifelong Learning data. Adaptive learning platforms; and Danny Hillis’ vision of a Learning Graph
Image Use: Creative Commons URL
New Blog for 2014
I have let go of a few years of blogs posts from garrygolden.net from 2008-2013!
Time to start fresh. Old URLs may still be live but not linked here!